実行ファイル doxygen は、 ソースを解析してドキュメントを生成するメインプログラムです。 より詳細な使用方法については、セクション Doxygen の使い方 を参照してください。
実行ファイル doxytag は、ソースのない外部のドキュメント(すなわち、doxygen によって生成したドキュメント) への参照を生成する場合にのみ、必要となります。 より詳細な使用方法については、セクション Doxytagの使い方 を参照してください。
オプションとして、実行ファイル doxywizard が使用できます。グラフィカルなフロントエンドであり、doxygen が使用する設定ファイルを編集したり、グラフィカルな環境でdoxygen を実行したりできます。 Mac OS X では、doxywizard は Doxygen アプリケーションアイコンをクリックすることで起動できます。
以下の図は、ツール間の関係およびそれらの間の情報の流れを示します (複雑なように見えますが、完全を目指しているからに過ぎません):
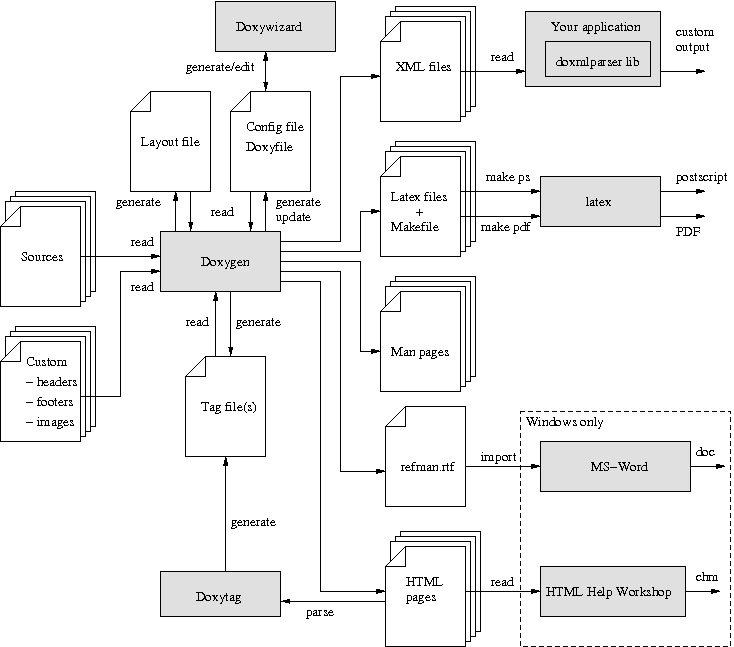
Doxygen information flow
doxygen は、設定ファイルを使用して、すべての設定を決定します。 各プロジェクトは、それぞれに設定ファイルが必要です。 プロジェクトは、単一のソースファイルだけでも構成できますが、 再帰的にスキャンできる完全なソースツリーでもあります。
設定ファイルの作成を単純化するために、 doxygen に設定ファイルのテンプレートを作成させることもできます。 これには、コマンドラインから-g オプションを付けて doxygen を呼び出します:
ここで <config-file> は設定ファイルの名前です。 ファイル名が省略された場合は、Doxyfile という名前のファイルが作成されます。 <config-file> という名前のファイルがすでにある場合は、doxygen は、設定テンプレートを生成する前にそのファイルを<config-file>.bak という名前に変更します。 ファイル名として - (マイナス記号) を使用すると、doxygen は標準入力 (stdin) から設定ファイルを読み込もうとします。 これにより、便利なスクリプトとして使うことができます。
設定ファイルのフォーマットは、(単純な) Makefile のフォーマットに類似しています。それは、次のような、いくつかの代入文(タグ)からなります:
TAGNAME = VALUE or
TAGNAME = VALUE1 VALUE2 ...
生成された設定ファイルのほとんどのタグは、デフォルトの値のままにしておくことができます。 設定ファイルについての詳細については、セクション 設定 を参照してください。
テキストエディタを使って設定ファイルを編集したくない場合は、doxywizard を参照してください。 このGUIフロントエンドでは、doxygen の設定ファイルの生成、読み込み、書き込みができ、ダイアログでオプションを設定できます。
少しの C/C++ ソースとヘッダーファイルからなる小さなプロジェクトでは、 INPUT タグは空のままにできます。この場合 doxygen はカレントディレクトリのソースを検索します。
ソースディレクトリまたはツリーからなる大きいプロジェクトの場合、 ルートディレクトリまたは複数ディレクトリを INPUT タグに指定し、1つ以上のファイルパターンを FILE_PATTERNS タグに追加します(例えば *.cpp *.h)。 パターンのうち1つとマッチするファイルだけが構文解析されます (パターンが省略された場合、ソース拡張子のリストが使われます)。 ソースツリーを再帰的に解析するには、RECURSIVE タグを YESにセットしなければなりません。 解析されるファイルのリストをさらに微調整するために、EXCLUDE と EXCLUDE_PATTERNS タグを使うことができます。 例えばソースツリーから test ディレクトリのすべてを除外するには、 次のようにします:
EXCLUDE_PATTERNS = */test/*
doxygenは、ファイルの拡張子を見て解析方法を決めます。 .idl または .odlという拡張子のファイルは、IDL ファイルとして扱います。 .java 拡張子のファイルは、Javaで書かれたファイルとして扱います。 .cs 拡張子のファイルは、C#ファイルして扱い、.py 拡張子のファイルには Python パーサーを使います。 拡張子が .php、.php4、.inc、.phtmlのファイルは、PHP ソースとして扱います。 .m という拡張子のファイルは、Objective-C ソースファイルとして扱います。 その他の拡張子のファイルは、C/C++ ファイルとみなして解析します。
もし既存の (従って doxygen がわかるドキュメントは一切付いていない) プロジェクトに対して doxygen を使い始めた場合でも、その構造や、ドキュメント化の結果についてその意味を理解できます。 それには、設定ファイルで、EXTRACT_ALL タグを YES に設定する必要があります。 すると、doxygen は、ソース中のあらゆる物にドキュメントが付けられているかのごとく振る舞います。
EXTRACT_ALL が YES に設定されてさえいれば、 ドキュメントのないメンバーがあっても警告が生成されません。
既存のソフトウェア作品を解析するに当たっては、ソースファイル中での、(ドキュメント付けられている) 実体とその定義とのクロスリファレンスを取ることが役に立ちます。 SOURCE_BROWSER を YES に設定すると、doxygen は、そのようなクロスリファレンスを生成します。 INLINE_SOURCES を YES に設定すると、ドキュメント内に直接ソースコードを取り込むこともできます (たとえば、コードのレビューアにとって役に立つでしょう)。
ドキュメントを生成するには、次のように入力します。
設定しだいで、出力ディレクトリの中に、html、rtf、latex、xml、そして man ディレクトリなどが生成されます。 名前からわかるように、これらディレクトリには、HTML、RTF、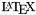 、XML
、XML および Unix-Man ページ形式 のドキュメントが格納されます。
デフォルトの出力先ディレクトリは、doxygen の起動ディレクトリです。 出力先のルートディレクトリは、OUTPUT_DIRECTORY を使って変更できます。 出力先ディレクトリ内での、ファイル形式用ディレクトリは、設定ファイルで、 HTML_OUTPUT、RTF_OUTPUT、 LATEX_OUTPUT、XML_OUTPUT、 MAN_OUTPUT タグを使って指定できます。 もし出力先ディレクトリが存在しないならば、doxygen はそれを作成しようとします (しかし、mkdir -p のように全体のパスを再帰的に作成したりは しません)。
生成された HTML ドキュメントを見るには、HTML ブラウザで html ディレクトリの index.htmlファイルを開きます。 カスケーディング・スタイルシート (CSS) をサポートするブラウザ (作者は、Mozilla、Safari、Konqueror、時にはIE6 を使って結果をチェックしています) を使えば、最良な形で結果を見ることができます。
HTML セクションのいくつかの機能 (GENERATE_TREEVIEW など) は、DHTML と Javascript をサポートするブラウザを必要とします。
検索エンジン (SEARCHENGINE を参照) を使う計画があるなら、PHP 対応のウェブサーバー (例えばapache、PHPモジュールインストール済み) を介してHTML 出力を見てください。
生成された ドキュメントは、まず コンパイラ (作者は最新の teTeX ディストリビューションを使います) を使ってコンパイルする必要があります。 生成されたドキュメントをコンパイルする手順を簡素化するために、doxygen は Makefile を latex ディレクトリに書き込みます。
Makefile の内容とターゲットは、USE_PDFLATEX の設定に依存します。 不可 (NO) に設定されていた場合、latex ディレクトリで make と打ち込めば、refman.dvi と呼ばれる dvi ファイルが生成されます。 このファイルは xdvi を使って見ることができます。また、make ps と打ち込む (これには dvips を必要とします) ことで PostScript ファイル refman.ps に変換できます。
一枚のページに 2ページ分を表示させるには、代わりに、make ps_2on1 を使用してください。 結果として得られた PostScript ファイルは PostScript プリンタに送ることができます。 もし PostScript プリンタが手元になければ、ghostscript を使って、PostScriptファイルを、お使いのプリンタ用に変換してみてください。
ghostscript インタプリタをインストールしてあれば、PDF への変換も可能です。 make pdf (または make pdf_2on1) とタイプするだけです。
PDF 出力を最良形で見るには、 PDF_HYPERLINKS タグと USE_PDFLATEX タグを YES に設定してください。 こうすれば、Makefileには、refman.pdf を直接ビルドするのに必要なターゲットだけが書き込まれます。
doxygenは、RTF 出力を、refman.rtf と呼ばれる単一のファイルに合成します。 このファイルは Microsoft Word にインポートできるように最適化されています。 フィールドを使ってエンコードされる情報があります。 実際の値を表示するには、すべて選択 (編集 - すべて選択) してから、フィールド更新 (右クリックしてドロップダウン・メニューからオプションを選びます) してください。
XML 出力は、Doxygenが集めた情報の塊で、それを構造化したものです。 クラス、名前空間、ファイルなど各要素にXML ファイルがあり、index.xml と呼ばれるインデックス・ファイルがあります。
combine.xsltというXSLT スクリプトファイルも生成されるので、XML ファイルを単一のファイルに合成できます。
Doxygen は、2つの XML スキーマファイル、index.xml用のindex.xsd と要素用のcompound.xsd を生成します 。 このスキーマファイルには、含まれる要素とそれらの属性、および構造を記述されます。 すなわち、XMLファイルの文法が記述されているので、確認したり、XSLTスクリプトの操作に使うことができます。
addon/doxmlparser ディレクトリにはパーサーライブラリがあり、XML出力を漸進的に読むために使えます。(ライブラリのインタフェースを知るには、addon/doxmlparser/include/doxmlintf.h を参照してください)
生成された man ページは、man プログラムを使って見ます。 man ディレクトリが man パス (MANPATH 環境変数を参照) に含まれていることを確認する必要があります。 man ページのフォーマットには能力に制限があるので、クラス図、クロスリファレンス、式など表現できないものがあります。
ソースにドキュメントを付けることをステップ 3 として提示していますが、新しいプロジェクトでは、もちろんステップ 1 でやるべきことです。 ここでは、コードはすでに記述されていて、その API 及び内部についてドキュメントを生成したいという状況を想定して、話を進めます。
設定ファイルで、EXTRACT_ALL オプションが NO(デフォルト) に設定されている場合、doxygenがドキュメントを出力するのは、ドキュメント付けされたファイル、クラス、名前空間についてだけです。 じゃあ、これらにはどうやってドキュメントを付けてやればよいのでしょう。 メンバー、クラス、名前空間に対しては、基本的に 2通りの方法があります。
-
メンバーやクラス、名前空間の宣言や定義の前に、特殊ドキュメントブロック を置きます。 ファイル、クラス、名前空間のメンバーに対しては、直後にドキュメントを置くこともできます。 特殊ドキュメントブロックについて、詳しくは 特殊ドキュメント・ブロック を参照してください。
-
特殊ドキュメントブロックをどこか別の場所 (他のファイルや他の位置) に配置し、かつ、ドキュメントブロック内に構造化コマンドを置きます。 構造化コマンドは、ドキュメント付けできる決められた実体 (メンバー、クラス、名前空間、ファイルなど) に、ドキュメントブロックをリンクします。 構造化コマンドについて、詳しくは、ドキュメント・ブロックの移動 を参照してください。
ファイルの前にドキュメント・ブロックを置く方法はないので、2番目のオプションしか使えません。 もちろん、ファイルメンバー(関数、変数、typedef、define) には明示的な構造化コマンドは必要ありません。特殊ドキュメント・ブロックをその前後に入れます。
特殊ドキュメントブロック内のテキストは、解析されてから、HTML や のファイルに書き出されます。
解析 (parsing) では、次のステップが実行されます:
-
ドキュメント内部の特殊コマンドが実行されます。全コマンドの一覧は、セクション 特殊コマンド を参照してください。
-
空白で始まり、その後に 1つ以上のアスタリスク (
*)、さらに 0個以上の空白が続く行では、空白とアスタリスクはすべて除去されます。
-
結果として空になる行は、段落区切りとして扱われます。 ですので、読みやすくするための新規パラグラフのコマンドを書く手間が省けます。
-
ドキュメント付けされたクラスに対応する単語には、リンクが作成されます (その 単語の前に % がついていると、リンクは作られず、% 記号は削除されます)。
-
テキストに特殊なパターンが見つかった場合、そのメンバーへのリンクが作成されます。 自動リンク生成がどのように働くかについて、詳しくはセクション リンクの自動生成 を参照してください。
-
ドキュメント内の HTML タグは、 ファイルに出力するため、解釈され、 形式に変換されます。 サポートされているHTML タグの一覧は、HTML コマンド を参照してください。
次 のセクションに行く /
インデックス に戻る
